The Death Master Database was analyzed with the following PERL script, hacked together to plow through ~10GB of raw text in just a few minutes. A much better and more elegant program is possible, but this gets the job done for the purposes of NumChk.
Outline of the this page:
1. quick overview of the structure of the SSDI file and the data format 2. screenshots available of the code because Visual Studio Code does a nice job of colorization.
3. Some annotation of the code for those that or just learning, or want to poke holes in the analysis
4. How the code was run with console redirect (>) operator for easy file output.
5. What the output looks like
6. Perl Code in txt form at the bottom for you to copy out if you want to use it.
for an overview of the data being processed, see SSDI section in SSN Dataset
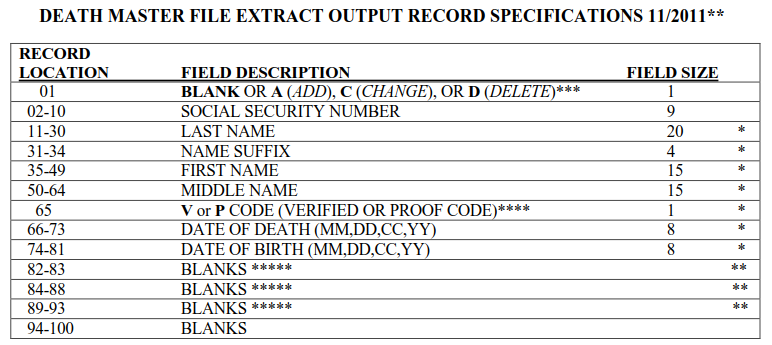
1. quick overview of the structure of the SSDI file and the data format
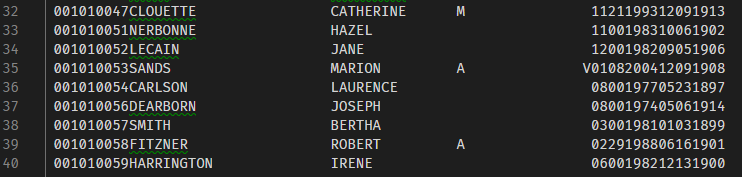
2. screenshots available of the code because Visual Studio Code does a nice job of colorization.
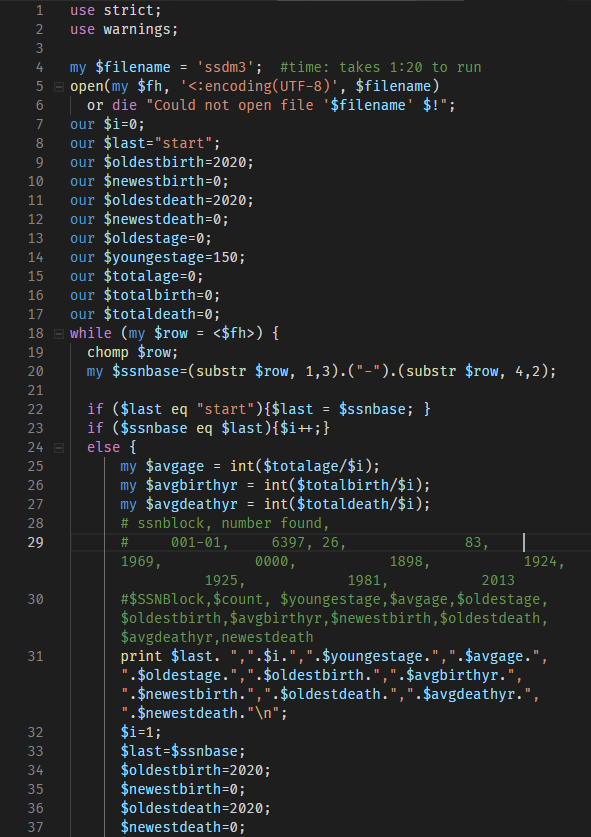
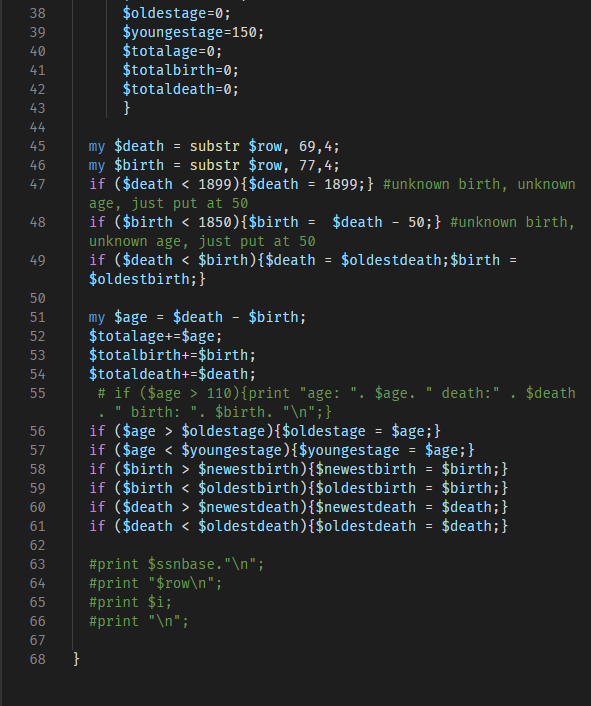
3. Some annotation of the code for those that or just learning, or want to poke holes in the analysis
Change the filename in line 4 to match your dataset. If your data came in more than one file, just match the filename here.
someday maybe i'll come back and annotate this, for now this stub is a place holder for me to add something interesting. if you actually care how this works and can't figure out out, email info@numchk.com and i'll finish this section.
4. How the code was run with console redirect (>) operator for easy file output.
C:\User\NumChk> perl parse.pl > output.csv
The dataset run had 3 files, so this was repeated once for each base file and results stored in a new output file. look at Line 4 of the program and change the name to point to the datafile, run, change the name, run again. In Windows/DOS, the '>' is a console redirect so instead of putting results out on STDIO (screen) it shoves it in a file (output.csv) in the same directory the program is run from.
5. What the output looks like
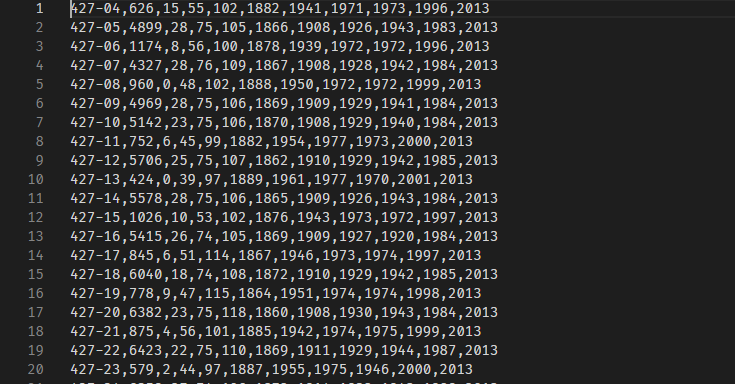
From here it's just data manipulation and repacking suitable for JS consumption and that is how part of the dataset for Numchk SSN was done. With this, 10GB of data was squished down to just less than 3MB so a summary could be presented for each SSN block. actually to get to 3MB, a few more tricks were run - subtract 1900 from dates and you save a few digits in base file, and add them back in in JS.
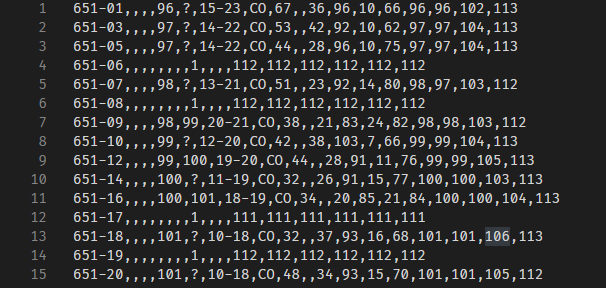
Here we see the additional manipulation of the data done (seperately) to smash the data down a little farther to improve load time. The zeros are removed, and Years are changed to subtract 1900 which effectively converts them to 2 digits. There isn't much data below 1900 so a few minus signs doesn't change the size much.
6. Perl Code in txt form for you to copy out if (in the extremely unlikely event you actually) want to use it.
Outline of the this page:
1. quick overview of the structure of the SSDI file and the data format 2. screenshots available of the code because Visual Studio Code does a nice job of colorization.
3. Some annotation of the code for those that or just learning, or want to poke holes in the analysis
4. How the code was run with console redirect (>) operator for easy file output.
5. What the output looks like
6. Perl Code in txt form at the bottom for you to copy out if you want to use it.
for an overview of the data being processed, see SSDI section in SSN Dataset
1. quick overview of the structure of the SSDI file and the data format
2. screenshots available of the code because Visual Studio Code does a nice job of colorization.
3. Some annotation of the code for those that or just learning, or want to poke holes in the analysis
Change the filename in line 4 to match your dataset. If your data came in more than one file, just match the filename here.
someday maybe i'll come back and annotate this, for now this stub is a place holder for me to add something interesting. if you actually care how this works and can't figure out out, email info@numchk.com and i'll finish this section.
4. How the code was run with console redirect (>) operator for easy file output.
C:\User\NumChk> perl parse.pl > output.csv
The dataset run had 3 files, so this was repeated once for each base file and results stored in a new output file. look at Line 4 of the program and change the name to point to the datafile, run, change the name, run again. In Windows/DOS, the '>' is a console redirect so instead of putting results out on STDIO (screen) it shoves it in a file (output.csv) in the same directory the program is run from.
5. What the output looks like
From here it's just data manipulation and repacking suitable for JS consumption and that is how part of the dataset for Numchk SSN was done. With this, 10GB of data was squished down to just less than 3MB so a summary could be presented for each SSN block. actually to get to 3MB, a few more tricks were run - subtract 1900 from dates and you save a few digits in base file, and add them back in in JS.
Here we see the additional manipulation of the data done (seperately) to smash the data down a little farther to improve load time. The zeros are removed, and Years are changed to subtract 1900 which effectively converts them to 2 digits. There isn't much data below 1900 so a few minus signs doesn't change the size much.
6. Perl Code in txt form for you to copy out if (in the extremely unlikely event you actually) want to use it.
use strict;
use warnings;
my $filename = 'ssdm3'; #time: takes 1:20 to run
open(my $fh, '<:encoding(UTF-8)', $filename)
or die "Could not open file '$filename' $!";
our $i=0;
our $last="start";
our $oldestbirth=2020;
our $newestbirth=0;
our $oldestdeath=2020;
our $newestdeath=0;
our $oldestage=0;
our $youngestage=150;
our $totalage=0;
our $totalbirth=0;
our $totaldeath=0;
while (my $row = <$fh>) {
chomp $row;
my $ssnbase=(substr $row, 1,3).("-").(substr $row, 4,2);
if ($last eq "start"){$last = $ssnbase; }
if ($ssnbase eq $last){$i++;}
else {
my $avgage = int($totalage/$i);
my $avgbirthyr = int($totalbirth/$i);
my $avgdeathyr = int($totaldeath/$i);
# ssnblock, number found,
# 001-01, 6397, 26, 83, 1969, 0000, 1898, 1924, 1925, 1981, 2013
#$SSNBlock,$count, $youngestage,$avgage,$oldestage,$oldestbirth,$avgbirthyr,$newestbirth,$oldestdeath,$avgdeathyr,newestdeath
print $last. ",".$i.",".$youngestage.",".$avgage.",".$oldestage.",".$oldestbirth.",".$avgbirthyr.",".$newestbirth.",".$oldestdeath.",".$avgdeathyr.",".$newestdeath."\n";
$i=1;
$last=$ssnbase;
$oldestbirth=2020;
$newestbirth=0;
$oldestdeath=2020;
$newestdeath=0;
$oldestage=0;
$youngestage=150;
$totalage=0;
$totalbirth=0;
$totaldeath=0;
}
my $death = substr $row, 69,4;
my $birth = substr $row, 77,4;
if ($death < 1899){$death = 1899;} #unknown birth, unknown age, just put at 50
if ($birth < 1850){$birth = $death - 50;} #unknown birth, unknown age, just put at 50
if ($death < $birth){$death = $oldestdeath;$birth = $oldestbirth;}
my $age = $death - $birth;
$totalage+=$age;
$totalbirth+=$birth;
$totaldeath+=$death;
# if ($age > 110){print "age: ". $age. " death:" . $death . " birth: ". $birth. "\n";}
if ($age > $oldestage){$oldestage = $age;}
if ($age < $youngestage){$youngestage = $age;}
if ($birth > $newestbirth){$newestbirth = $birth;}
if ($birth < $oldestbirth){$oldestbirth = $birth;}
if ($death > $newestdeath){$newestdeath = $death;}
if ($death < $oldestdeath){$oldestdeath = $death;}
#print $ssnbase."\n";
#print "$row\n";
#print $i;
#print "\n";
}
NumChk
info@numchk.com